
Pushing code is easy, there are a bunch of tools out there today that automate those deployments. But there’s often an overlooked aspect of deployments that are still done manually. Database deployment is often still a manual process. These deployments often slow down our delivery pipelines, they are slow, error-prone and resource intensive because it’s still a manual process that interferes with a clean hand-off between development and operations.
Some people have referred to this as the “Velocity Gap”. The blocker that is our biggest constraint in delivery because we can only move as fast as our slowest member, and more often than not that ends up being the database implementation. If the goal is that we deliver 10 times a day, 10 manual database deployments can create quite the bottleneck.
Similarly to security, the reason why the database is causing such a roadblock is because it is typically the last team to be brought into the life cycle. Databases cannot be reverted or replaced like application features. It is designed to preserve and protect data, and for that reason it must be preserved itself. Solving this part of the application delivery is a complex one, because unlike the delivery of code, where a roll-back consists of deploying the previous build artifacts, the database is always in constant motion and more often than not you can’t just go back to the previous state-in-time because the data entered into the system must still be preserved. For example, in an order based system, you can’t just blow away the last 3 days of purchases because you found a bug and need to roll-back.
This fundamentally goes to how databases are designed. Just like developers had to learn how to structure their code to support automated and unit testing, database architects must now learn how to build out resilient databases that will support the devOps cadence of release. To successfully bring the database into the devOps fold, database administrators should be integrated into the team, learn about development, and trust the development process. DevOps means having cross-functional teams, so the database administrators should be a part of the team and able to weigh in on the architecture, in the traditional way of doing things, when a change happens the database admin typically doesn’t know why the change is happening or how it will impact the overall product. Bringing them to the team will help them understand not only the function of the product, but enable them to weigh in on the architecture.
This is extremely important because our traditional data structures in a database don’t support a devOps model because we’re missing a layer of abstraction. Often times when we look at restructuring our database to support the devOps deployment model. When choosing how to structure our database and it’s deployment process, there are some key fundamentals that need to be taken into account:
- Testable: I can test any database change before running it on the Production database.
- Automated: I can automate the whole process so that I can’t get it wrong.
- Trackable: Each database should have a log of what has been done to its schema.
- Atomic: The update process must either be completed successful or entirely rolled-back.
- Recoverable: Each update should automatically make a backup in case the worst happens.
For this reason, one model I’ve found that works extremely well is the concept of having core data tables that handle our data and then an interface database responsible for views, stored procedures, and business logic that exists outside of the raw data.
By breaking out into 2 separate databases on the same server, it makes it easy to have both facade databases “in-flight” while still relying on the core-data to remain constant. Small changes, updates and features are applied to one facade to support the canary build or blue-green model of deployment.
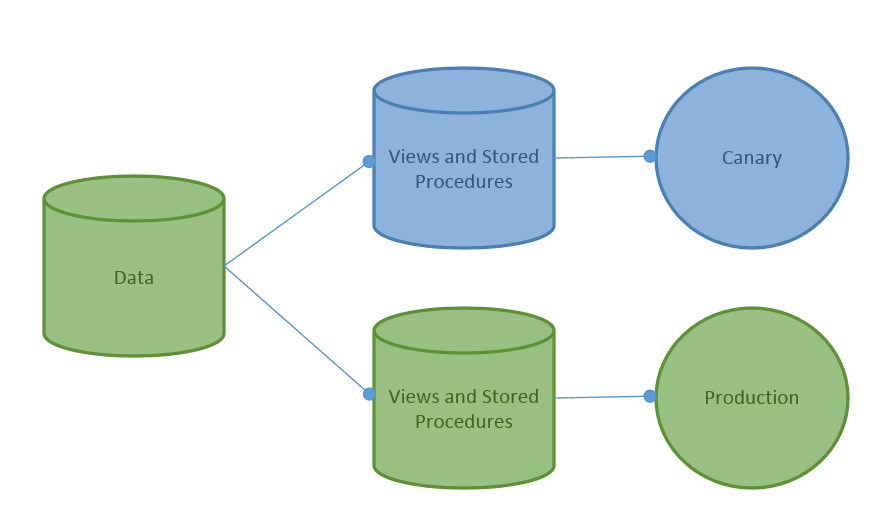
By breaking out the database code and isolating it from the raw data store, it allows us to run a side-by-side in production using a canary or ring deployment.
Now, does this work in every case? No. But it does go a long way to allowing us to perform rapid deployments and roll-backs of many of our changes while still preserving our “in-flight” data as in the case of various e-commerce applications. By abstracting our database “functionality” in the form of views and stored procedures in one database and the raw data in another, we can roll-back the changes quickly while preserving our actual data.
Fundamentally though, this is going to change the structure of your deployments and artifacts. You need to bring your DBA’s in early and explain the reasoning behind the structure and what it means in practical terms to them.



{kind=link}
Nice, can you go into more detail about blue-green deployments?
Basically you have what amounts to two live sites, then you roll your DNS between the two alternating which one is your production server